
Mitä ongelmaa ratkaistaan ja miksi?
- Rajaliikenteen määrä aiheuttaa vaatimuksia Tullin henkilöstötarpeessa. Mikäli rajan ylittävä liikenne kyetään ennakoimaan, on henkilöstöresurssitarpeiden kartoittajalla hyvät edellytykset tehtävän hoitamiseen.
- Kun henkilöstöresurssit ovat liikenteeseen nähden oikeassa suhteessa, liikenteen sujuvuus kasvaa eikä ruuhkia rajanylityspaikalla pääse syntymään.
- Tulli pyysi Valtiokonttoria laatimaan ennustemallin liikennevirtojen ennakointiin. Ennustemallin laatiminen on vielä kesken.
Mitä tehdään?
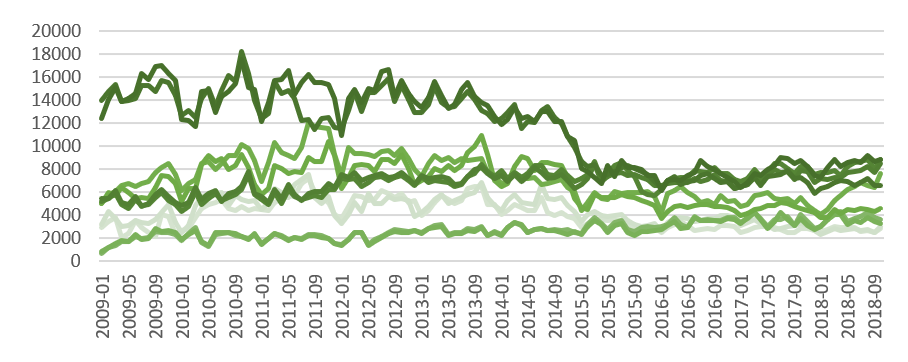
Tulliasemia on runsaasti, liikennettä molempiin suuntiin ja myös ajoneuvotyypit vaihtelevat. Ennustettavia liikennevirtoja on siis runsaasti (ks. kuva alla).
Miten lähestyä tämän kaltaista ongelmaa?
- Meillä on dataa rajaliikennemääristä tulliasemittain ja ajoneuvotyypeittäin. Voimme olettaa, että ilmiöön vaikuttavat esimerkiksi myönnettyjen viisumien määrä, valuuttakurssi vaihtelut, yleinen taloudellinen tilanne. Toisaalta voimme löytää indikaattoreita liikennemääriin esimerkiksi Googlen hakumääristä. Myöskään sosiaalisesta mediasta saatava data ei ole poissuljettu. Kaikki tämä data on avointa ja saatavissa kohtuullisella vaivalla.
- Datan keräämisen jälkeen olemme pyöritelleet erilaisia malleja, joilla useasta lähteestä yhdistetystä datasta saadaan todellista liikennevirtaennustetta. Päädyimme valitsemaan neuroverkon.
Neuroverkko on laskennallinen menetelmä, jossa dataa painotetaan valtavalla määrällä erilaisia painoja ja painotetuista datapisteistä muodostetaan ennuste. Painokertoimet valitaan optimaalisesti käyttäen optimointialgoritmeja. Kyseessä on ohjattu koneoppimismenetelmä. Neuroverkkomalli kykenee käsittelemään big dataa ongelmitta, ja voimme ennakoida useita sarjoja yhdellä mallilla.
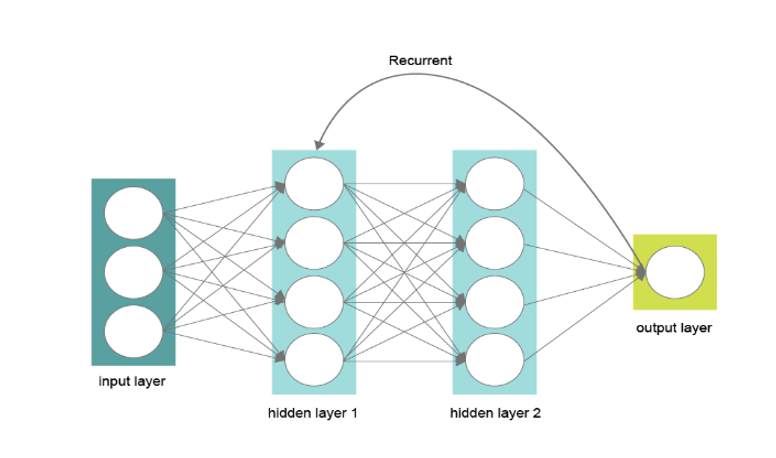 Yllä oleva kaavio kuvaa yksinkertaisen neuroverkon rakennetta. Syötekerros (input layer) on data, jota on käsitelty siten, että se on muunnettu ohjattuun oppimismenetelmään sopivaksi. Data painotetaan piilokerroksissa (hidden layer), joka koostuu neuroneista ja niiden välisistä yhteyksistä. Piilokerroksesta painotettu tieto tuodaan tulostekerrokseen (output layer), joka vastaa ennustetta.Käsiteltävä data jaetaan kolmeen osaan, usein 60/20/20 jaolla. Harjoitusdatasta (training set) mallin on tarkoitus ”oppia” dataan liittyvää informaatiota. Validointidatan (validation set) avulla tarkastellaan yli-/alisovittamisongelmaa. Opetetulla mallilla tuotetaan ennusteita ja verrataan sitä testidatasta (test set) löytyvään toteutuneeseen arvoon.
Yllä oleva kaavio kuvaa yksinkertaisen neuroverkon rakennetta. Syötekerros (input layer) on data, jota on käsitelty siten, että se on muunnettu ohjattuun oppimismenetelmään sopivaksi. Data painotetaan piilokerroksissa (hidden layer), joka koostuu neuroneista ja niiden välisistä yhteyksistä. Piilokerroksesta painotettu tieto tuodaan tulostekerrokseen (output layer), joka vastaa ennustetta.Käsiteltävä data jaetaan kolmeen osaan, usein 60/20/20 jaolla. Harjoitusdatasta (training set) mallin on tarkoitus ”oppia” dataan liittyvää informaatiota. Validointidatan (validation set) avulla tarkastellaan yli-/alisovittamisongelmaa. Opetetulla mallilla tuotetaan ennusteita ja verrataan sitä testidatasta (test set) löytyvään toteutuneeseen arvoon.

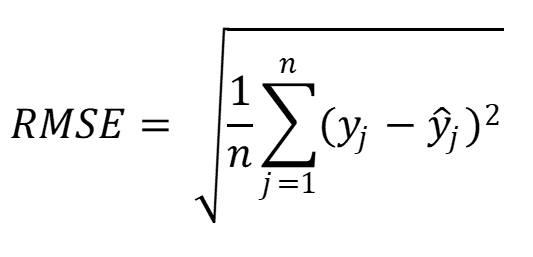 Ennusteen ja toteutuneen arvon välinen virhe lasketaan käyttäen esimerkiksi keskineliövirheen neliöjuurta (Root-Mean Square Error, RMSE). Malleja verrataan toisiinsa virheen perusteella.
Ennusteen ja toteutuneen arvon välinen virhe lasketaan käyttäen esimerkiksi keskineliövirheen neliöjuurta (Root-Mean Square Error, RMSE). Malleja verrataan toisiinsa virheen perusteella.
Neuroverkon opettaminen saattaa viedä aikaa, sillä muokattavia parametreja on runsaasti ja yksittäisen mallin laskeminen on vaativa tehtävä. Alla keskeneräisen mallin tuottama testiennuste raskaan liikenteen määrästä Nuijamaan raja-asemalla.
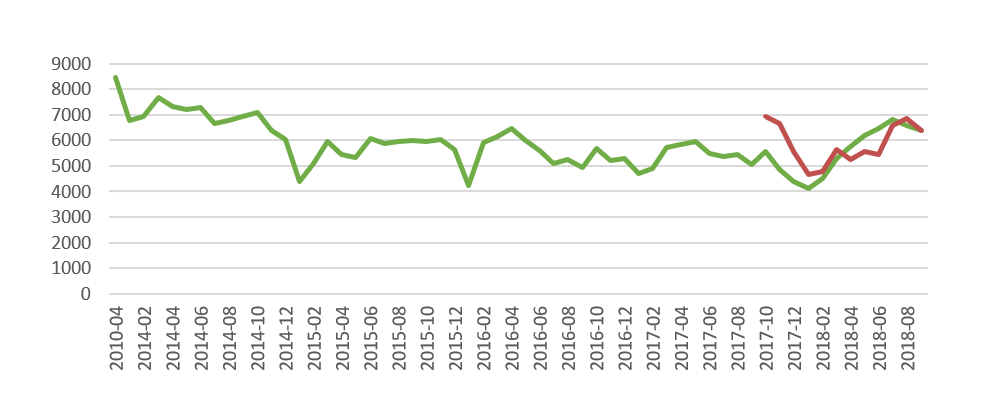
- Tällä hetkellä mallin hyperparametrien (neuronien lukumäärä, optimointimenetelmä jne.) optimaalinen valinta on siis kesken. Etsimme siis mallia, jonka ennustevirhe on pienin.
Haluatko kuulla lisää tai keskustella mahdollisesta yhteistyöstä?
Ota meihin yhteyttä:
- analysointipalvelu (at) valtiokonttori.fi